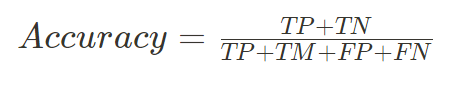인공지능에서 Metrics는 해당 모델의 성능을 판단하는 평가 지표를 말한다. 이를 계산하는 방법이 꽤 다양한데, 그렇기 때문에 어떤 모델이냐, 어떤 문제냐에 따라 적절한 metrics를 사용해야 한다. 그 중 대표적인 Metrics 몇가지를 정리해 보려고 한다. 우선 비가 오는지 안오는지를 맞추는 경우를 생각해 보자. 비가 오면1 오지 않으면 0이다. Confusion Matrix Predicted Positive (1) Negative (0) Actual Positive (1) True Positive (TP) False Negative (FN) Negative (1) False Positive (FP) True Negative (TN) TP : 실제로 비가 왔고 (Actual Positive) 모델..